It’s hard not to be compelled by the promises of electronic monitoring (EM) paired with machine learning (ML), artificial intelligence (AI), and edge computing. Cameras and algorithms that never stop, providing near-real-time insights into what is being caught, where, and how.
This article, "Monitoring Fishing Activity on the Edge," which deals with EM and edge AI for longline fisheries, makes its case well. It is forward-looking, technically grounded, and persuasive in its central proposition: that combining onboard processing with machine learning can dramatically improve transparency, reduce review costs, and bring fisheries monitoring closer to real time.
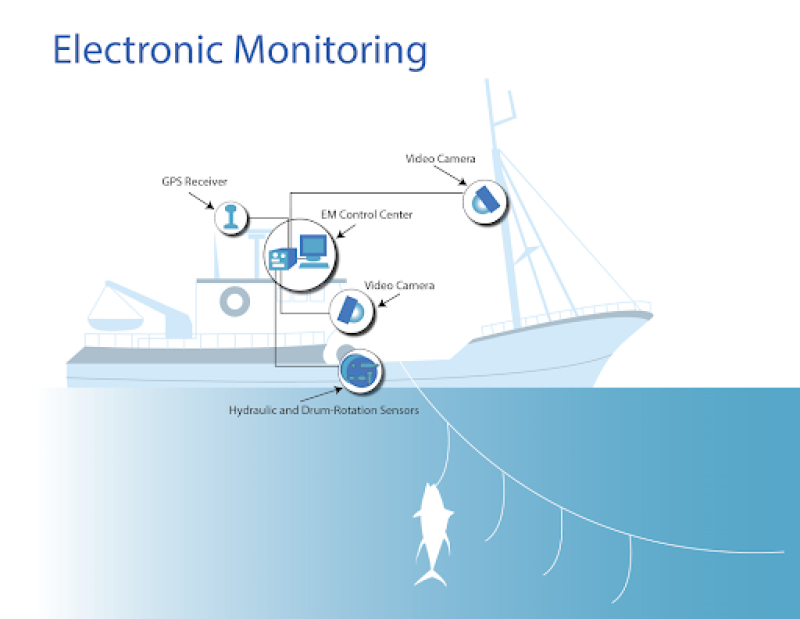
Source: https://www.fisheries.noaa.gov/new-england-mid-atlantic/commercial-fishing/electronic-monitoring-northeast
For those of us involved in MCS and fisheries management, which suffer from delayed, incomplete, and often unreliable data, the idea of near-real-time catch verification is not just attractive—it is overdue. The longline sector, in particular, has long operated in a space where visibility is limited, observer coverage is sparse, and verification is often retrospective at best.
So yes, the technology is promising. But as I read the piece, what struck me was not what it said, but what it did not.
Because the discussion of cameras, models, and deployment strategies is all about data management and processing… but not a lot about who owns it, who controls it, and who ultimately benefits from it.
The article speaks confidently about systems that convert raw video into annotated datasets and about using those datasets to train models capable of identifying species and verifying catch. It gestures towards openness by mentioning publicly available tools and baseline datasets. It highlights efficiency gains and scalability.
The model is compelling: Raw footage becomes labelled imagery >> Labelled imagery becomes training data >> Training data becomes model weights (the core process of ML- essentially converting massive datasets into actionable knowledge and numerical patterns), and then >> Model weights become products.
At each step, value is created… And at each step, the question grows sharper: where does that value go?
This is not a theoretical concern. It is a structural feature of how ML systems develop; the more data they ingest, the better they perform. The better they perform, the more valuable they become. Over time, the models themselves—refined through exposure to vast quantities of real-world data—become proprietary assets.
In the context of fisheries, that data does not come from nowhere.
It comes from vessels operating in sovereign waters, from fish caught under national jurisdictions, and from fisheries that coastal states here in the Pacific are responsible for managing.
And yet, if the architecture of these systems is not carefully designed, the long-term value generated from that data can easily accumulate elsewhere.
EM deployments, especially when combined with edge AI, are more than monitoring and compliance tools. They are also a data-harvesting system that generates continuous streams of information for monitoring and training increasingly sophisticated models.
If those models—and the datasets that underpin them—are controlled by vendors, then over time, a form of dependency will emerge.
While countries receive improved monitoring in the short term, developers/vendors accumulate data and refine models in the long term… And the balance of value shifts accordingly.
As I wrote in the past, I still struggle to read much about some basics:
Who owns the footage captured on board?
Who has rights to the annotated datasets derived from it?
Who controls the trained models built using that data?
Can those models be transferred, replicated, or independently audited?
These are not peripheral questions. They go to the heart of what this technological transition means.
Without clear answers, there is a real possibility that image libraries derived from sovereign fisheries become proprietary training sets. That model weights—refined over years of deployment in specific regions—become locked within commercial platforms, and then the countries that contributed the raw material find themselves purchasing back the analytical capability built from their own data.
It seems that along the way, the terms governing data ownership and intellectual property are either left vague or treated as secondary to immediate operational benefits. By the time the system is mature, the structure is already set, and at that point, renegotiating ownership or access becomes considerably harder.
Don’t get me wrong… this is not an argument against EM and the use of edge computing; all the opposite, these tools have the potential to address long-standing weaknesses in fisheries governance. They can improve compliance, support science, and reduce the opacity that has long characterised parts of the industry.
But technology does not arrive in a vacuum.
It arrives embedded in business models, contractual arrangements, and institutional contexts that shape how benefits and costs are distributed. And in the case of EM and AI, those distributions are not always obvious at the outset.
The WCPO provides a particularly relevant context for this discussion, as it is here that some of these systems are being piloted or considered. It is here that the stakes are high—not only in terms of fisheries management, but in terms of economic value, data sovereignty, and long-term control over marine resources.
The narrative, however, remains heavily weighted toward the technological promise these systems are bringing, which is real.
But the parallel narrative—about data sovereignty, intellectual property, and value capture—seems underdeveloped… and this imbalance matters: If the first wave of deployment proceeds without clear data governance frameworks, the second wave will inherit those assumptions. By then, the leverage to reshape them may be reduced.
This is not unfamiliar territory… data generated in one place, processed in another, monetised elsewhere. Value chains that begin with raw inputs and end with high-value outputs are often concentrated in the hands of those who control the intermediate steps.
The difference is that this time, the resource is not just the fish. It is also the data about the fish. And data, unlike fish, accumulates and compounds. It becomes more valuable the more of it you have.
Without them, transparency, compliance, and even sustainability may improve, but the underlying distribution of value becomes more skewed.
As said, this is a really good article that makes a strong case for what these technologies can achieve.
I would like to see more articles on what they may be doing unintentionally. In the end, with EM “seeing” everything, only part of the story is told; the other part is deciding who gets to own what is seen—and what is built from it.